
Indexing a web page is one of the 3 stages of search operation. Indexing is the step that follows crawling, also known as crawl, and precedes the processing and ranking of web pages.
Indexing requires particular attention if you want to better position a web page on search engines. That’s why I have decided to centre this article around it and explain to you a bit more in detail what its interest is, for the search engine and for you, website owners.
In this article, I will give you the definition of indexing, I will tell you why it is important in an SEO strategy, and how to check if your pages are indeed present in Google’s index.
Definition of indexing in a search engine Indexing is defined by a web page that has been crawled by a crawling robot and whose content has been analysed, then stored in the search engine’s index. A URL that has been indexed can be displayed on the search results pages in response to a query made by an internet user.
Indexing is an important step of an SEO service in which the consultant will set goals to index as many web pages of a single website as possible.
Why is it important to get a web page into the search engine’s index? If several web pages are indexed, meaning present in the search engine’s index, they can hope to be displayed in the search results pages, in response to an information need expressed by an internet user in the form of a query (a keyword or a search expression).
An indexed web page is a page that has sparked initial interest. Not all web pages are automatically indexed. There are relevance criteria that URLs must meet before being indexed.
To summarise:
- A page that is not crawled cannot be indexed and ranked in Google’s search results pages.
- A page that is crawled but does not meet several relevance criteria cannot be indexed or ranked (positioned).
- A page that is crawled and meets the relevance criteria is indexed and ranked. Today, indexing mainly refers to the procedures and actions aimed at ensuring that a website’s pages are properly accounted for by search engines, using tactics like XML Sitemap, site organisation, and internal linking. Historically, this terminology referred to the stage of registering a website in the various “indexes” of search engines.
What is a crawling robot? These robots, also known as spiders, crawlers, or bots, explore the internet through the links on each page to index as many web pages as possible. If you do not want to index certain pages of a website, you can notify Google directly via the Google Search Console. The robots.txt file is used to signal to indexing robots that a certain page should not be indexed in the organic search results.
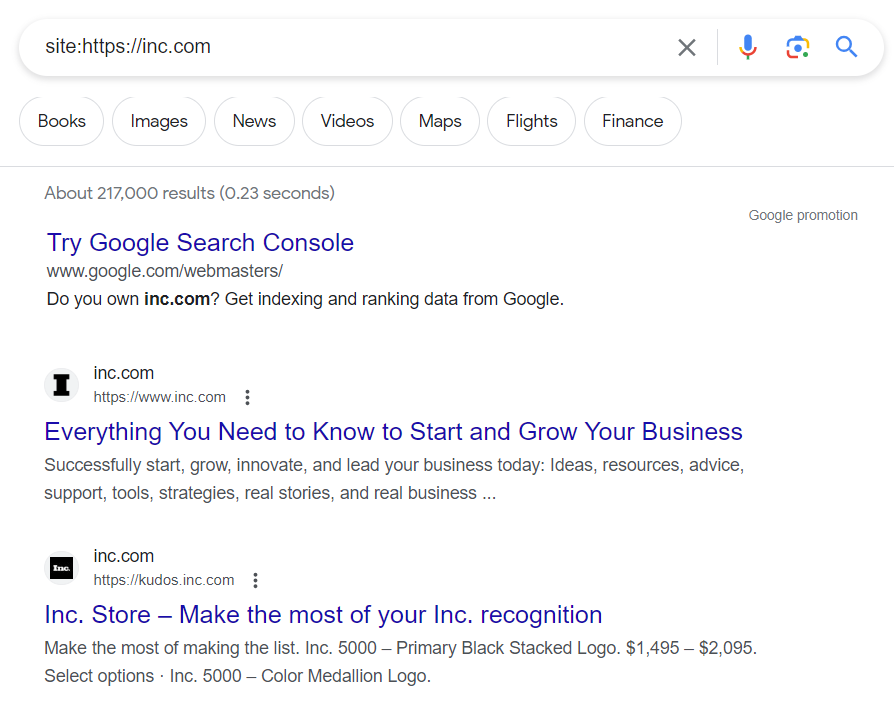
Knowing if your site or a URL of your site is indexed You have the opportunity to know if one or more URLs of your site exist in the database of Google’s index. For that, go to Google search
And enter the following Google command: site: the URL you wish to analyse.”

If your page or the pages of your site are in Google’s databases, it will provide you with a corresponding number of results, otherwise you will see nothing.
Can we ensure that our pages will be present in Google’s index? There is no certainty that a page will never be present in Google’s index, and vice versa. However, organic SEO can increase the guarantee of indexing one or more URLs on your website. To do this, you must work on the elements that will affect indexing.
Create a sitemap The sitemap is an XML file (a sitemap can also be in HTML format, but this is becoming less and less common) that includes all the URLs within a website and their relationships. Inside the sitemap, you will find all the HTML pages, as well as the URLs of images, videos, and PDFs if you have any.
The benefit of the sitemap.xml is that it allows crawling robots to explore the pages of your site much more quickly and easily. My opinion is that while the sitemap is very useful for large sites, its impact is somewhat less for small sites with only a few dozen pages.
Write an excellent title tag The title tag is one of the most important HTML elements when you want to improve your site’s SEO. It allows crawling robots to understand the general theme of the page before reading its content.
If you write a title tag within the norms, i.e., a relatively short title (between 50 and 60 characters maximum for full display on the search results pages) and including at least one search expression related to the page’s content, you will have more assurance that your URL will be taken into account in the index.
Quality content The content within your page must comply with the semantic and lexical rules applicable to natural language. Preferably short sentences, constructed in accordance with RDF triple writing. Your content must include not several times the same keyword but entities and types of entity that can be associated to form a sentence.
Example of RDF triple involving two types of entity + one attribute: The car is red in colour
Here “car” = entity, “is red in colour” = attribute (characterising the entity), “red” = value (which can also be an entity)
Internal linking and PageRank flow A site is more likely to have its pages indexed if those pages are linked to each other. The more a page receives links from other internal pages with strong semantic and lexical similarity or proximity, the more likely that page is to be in Google’s index.
One link = one vote.
If a page receives 3 links from 3 different pages, then it receives 3 votes. It is therefore considered by the search engine bots as factually more important than a page receiving no link/vote.
Page popularity A page that receives links from pages outside the site is also a greater guarantee of indexing. However, it is still necessary for the links to come from:
- an indexed page
- a page with strong semantic and lexical similarity
- a page that is linked with other pages on the same site
- a page benefiting from external links Indexing a web page is not something trivial that should be neglected when practising SEO. It must be watched like a hawk.